Apologies in advance. This is probably the geekiest post I’ve ever done.
To get an SSH client working – with a reasonable response time – on a 200mhz ARM chip a few years ago, I had to optimize some crazy things. One of those things was the generation of prime numbers, which are needed to create new public keys.
You may have heard that it’s very difficult to factor large numbers. This is true, but it’s actually a lot easier to determine whether a large number is “probably prime”. Most prime number generators create a random number from a secure source of entropy and then run it through a Miller-Rabin test, which can identify composite (non-prime) numbers. If the test doesn’t prove that a number is composite, then there’s at least a ¾ chance that it’s prime. You can perform the test multiple times to improve those odds. More info here: Miller-Rabin test
The Miller-Rabin test can be pretty time consuming, though, and since you may need to run it against many random numbers before you’ll find one that’s prime, it would be nice to weed out obvious composites beforehand. For example, you wouldn’t want to test an even number since that’s obviously divisible by 2. So here’s a shortcut I came up with that I call the “CJC prime number sieve”.
The Sum-of-Digits Trick
I thought I would be able to gloss over this part of the explanation by throwing out a few links and saying “go read about the (name) theorem!” But a google search only turns up some anecdotal descriptions, and wikipedia barely devotes an entire sentence to it (here: Modular Arithmetic).
There’s a fairly well-known trick for finding out if a number is divisible by 3: add the digits, and if the sum of the digits is divisible by 3, so is the original number. If it’s not, the original number is not. For example, 4401 is divisible by 3 because 4 + 4 + 0 + 1 = 9, and 9 is divisible by 3. 512 is not, because 5 + 1 + 2 = 8, and 8 is not divisible by 3. (This trick also works for 11 and 9 but these are emo numbers that don’t get as much attention.)
So why does this work? As you can guess from the wikipedia link above, it has to do with modular arithmetic. In (mod k) space, the only numbers that exist are integers from 0 to k - 1. Coders recognize this as being the way all int math works on a computer: a byte can represent a number “mod 256”. It turns out that in (mod k) space, you can cancel out a factor if that factor is relatively prime to k.
Say what? Okay, “relatively prime” just means two numbers don’t share any factors. 9 and 10 are relatively prime because 10 = 2 x 5, and 9 = 3 x 3. But 4 and 6 aren’t, because they share the factor 2.
Sooo… since:
20 = 2 (mod 9)
and 20 is relatively prime to 9, you can figure out 40 mod 9 by factoring out the 20, and replacing it with its equivalent in (mod 9) space, 2:
40 = 2 * 20
2 * 20 = 2 * 2 = 4 (mod 9)
The reason this works well for finding numbers divisible by 3 is that:
4401 = (4 * 1000) + (4 * 100) + (0 * 10) + 1
and:
10 = 1 (mod 3)
Aha! So factoring all the 10s out and replacing them with 1s gives us:
(4 * 1000) + (4 * 100) + (0 * 10) + 1 (mod 3)
(4 * 1) + (4 * 1) + (0 * 1) + 1 (mod 3)
4 + 4 + 0 + 1 (mod 3)
9 (mod 3)
0 (mod 3)
and any number that’s 0 in (mod 3) is of course divisible by 3.
The reason 9 and 11 work is that 10 mod 9 = 1, and 10 mod 11 = -1. (The -1 means you have to do alternate add/subtracts instead of just summing the digits, but it’s not worth obsessing over in this article.)
Making a sieve
So that’s exciting… if you do a lot of dividing by 3. But how does this help discover primes?
Well if computers worked in base 10 instead of 2, we’d now have a pretty fast way of determining if a really large number were divisible by 3. And I hope you won’t think I’m being pedantic if I point out here that if you make up a random number, it has about 1/3 chance of being divisible by 3. :)
Let’s say instead of working in base 10, we were working in some other base B that was relatively prime to a lot of interesting numbers. Ideally we’d like to be in a base B such that
B = 1 (mod n)
for as many n as possible. One nice coincidence is that
256 =
255 + 1 =
(3 * 5 * 17) + 1
or
256 = 1 (mod 3) and
256 = 1 (mod 5) and
256 = 1 (mod 17)
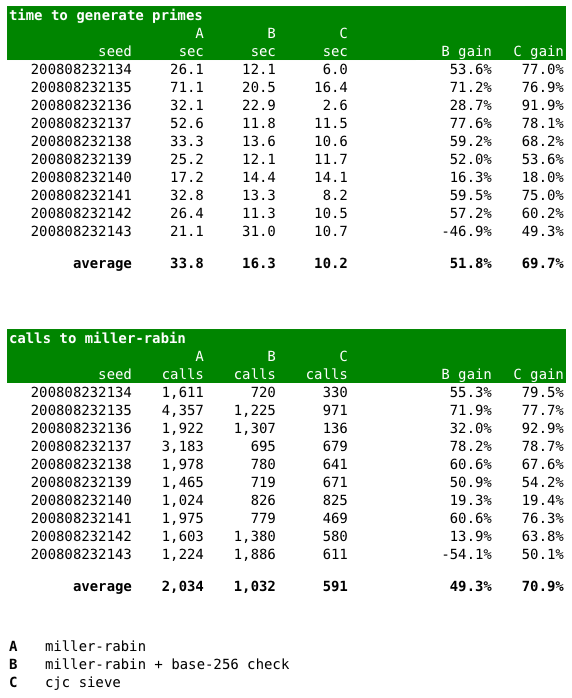
That means that in base 256, summing the digits will tell you quickly if 3, 5, or 17 is a factor. Summing the base-256 digits of a number also goes by the name “adding the bytes in the binary representation”. It actually helps a lot, as you can see from timings at the end of this article.
If we’re willing to leave powers of 2, though, we can do better. It just so happens that we can construct a base that’s relatively prime to a handful of small primes, yet is close to a power of 2. The key is noticing that, in the 256 case above, multiplying a few primes together and then adding 1 created a number that was both relatively prime to all those primes, and was equal to 1 in each of the primes’ (mod k) spaces.
Think of it this way. If A, B, and C are all prime, then A x B x C will equal 0 in (mod A) because it’s a multiple of A. Same goes for B and C for the same reason. Adding 1 makes it equal 1 in all three (mod k) as long as the primes are all greater than 2. And that also means the resulting number is no longer a multiple of A, B, or C, which makes our new number relatively prime to them. In short, we can construct a base that’s relatively prime to a set of primes, and is equal to 1 in each of the primes’ “mod spaces”, by just multiplying the primes together and adding 1.
We want the base to be close to a power of 2 to preserve our entropy source.
If we grab 8 bits (0 - 255) from a secure random pool, but we want a smaller
base like 250, we have two choices. We can mod the random byte (rand % 250)
to wrap into range, or we can just discard and retry when we get a byte
that’s out of our preferred range. If we mod-and-wrap, though, we’re giving
more weight to results in the wrapped part – numbers like 1 are going to be
more common because both 1 and 251 will mod-wrap to them. That ruins the
“secure” part of our randomness, so we need to go with the discard option. And
if we have to discard some bytes, we’d like to pick ranges to minimize the
chance of a byte being discarded, which means choosing ranges that are as
close to a power-of-2 range as possible.
One nice possibility is:
3 * 5 * 7 * 11 * 13 * 17 * 19**2 * 23 + 1 = 2119382266 = 0x7e5334fa
That’s a base that covers 98.7% of the 31-bit range, so it won’t cause many random digits to be discarded, and it’s relatively prime to the first 8 primes excluding 2. (We can ensure that a number isn’t divisible by 2 by just setting its lowest bit to 1 – a bonus for working in base 2!)
Let’s Go!
At this point, the code should just write itself. To generate a 1024-bit random prime, we need to figure out how many “digits” that would be in a base-2119382266 number, and what the range would be on the highest digit. We’ll lose some of the 1024-bit range because our new base doesn’t map exactly to the desired range, but we’ll never lose more than a single bit’s worth. (There’s probably a fancy proof for this, but if you think about it, you can reason it out pretty quickly in your head.) You already lose 2 bits for any prime, because you need to set the high bit to ensure a prime number of the desired size, and you need to set the low bit to ensure an odd number, as mentioned above.
For a 1024-bit prime, that means a 34-digit number with the highest digit set
to 2. For a 2048-bit prime, it’s a 67-digit number with the highest digit
between 5 and 8 inclusive. (You can play around with other sizes by calling
computeParams in the attached code.)
We can then generate, for a 1024-bit prime, 33 “digits” of 32-bit machine words, masking off the high bit and retrying any time we get a “digit” bigger than (base - 1). Set the high “digit” to 2 (or select a digit at random for other bit choices) and we’re done.
A quick shortcut here: Normally we should sum the digits, and then find the mod of that sum against each of our 8 primes. However, we already have a really convenient thing here: base - 1 is a multiple of all of 8 primes (by design), so we can mod the sum by (base - 1) as we add, and not lose any information, keeping the sum small enough to fit into a 32-bit word.
After summing, a few small mod operations tell us if the generated number is divisible by 3, 5, 7, 11, 13, 17, 19, or 23. If it is, we can loop back and generate another number immediately, skipping the Miller-Rabin prime test. If it passes, we still dump it into Miller-Rabin for final verification – the sum check just lets us quickly discard any simple composites.
Code and Results
I wrote a proof-of-concept in scala, and hosted it in git here:
git clone http://www.lag.net/robey/code/cjc/
It includes an implementation of CJC in base 2119382266, alongside a prime number generator that just uses the standard Miller-Rabin prime test by itself, and a variant of the standard M-R sieve that checks the base-256 primes (3, 5, 17) first.
The test code generates 5 primes from each algorithm, using a random number seed given on the command line. (By the way, never use the built-in random number generator like this code does! Use a secure one. I used a seeded generator so the results would be repeatable, which is exactly what you don’t want in the real world.) I’ve posted my own results in a chart below: Using the base-256 check alone gives a 2x speedup, and using CJC gives over 3x! The primary increase, according to the second chart, appears to be due to cutting back on calls to the Miller-Rabin algorithm. The more candidates we can discard before trying M-R, the better.
(By the way, ignore how long these algorithms are taking in wall-clock time. I ran them in a standard JVM without JIT. In real life, you would definitely want this to be in JIT or possibly even C – horrors!)
Anyway, hopefully this is an interesting technique for filtering primes. And the name CJC? It’s named after my friend Communist J. Cat.