
Git is really confusing for new users who have come over from subversion or perforce. On one hand, I can admire, in a sort of detached objective way, Linus’s commitment to making the tool bare-bones and focusing on trying to make the command-line tools as fast as possible. On the other hand, many of the defaults are maddeningly obscure, and there are large gaps where the the starship’s hallway just ends in a catwalk and piles of exposed wiring. “Watch your step here. We haven’t felt like finishing this part.”
So, cool that git has reached a critical mass where it’s bringing DVCS (“distributed version control systems”) to people who never would have tried them before. But it means that, as opposed to bazaar, we need to share a lot of knowledge and best practices in order to make it work smoothly. Consider this a sequel to my last git post.

Single master
A few times I’ve heard people argue that if you’re using git (or any DVCS) and you have a central repository, then “You’re Doing It Wrong”. I disagree.
I think most software projects, whether they are a library, a server, or a website, have a single linear series of releases. Toaster 1.3.2 is followed by Toaster 1.3.3, etc. On this macro scale, each release is meant to be an improvement or progression over the previous one. If you have this kind of system, then you’re probably going to have a single repository somewhere which holds the “authoritative” copies production or release branches, even though lots of people will have local copies of them.
DVCS makes it easy to have a large cloud of coders, each with their own copy of the source, equally authoritative from git’s point of view, and therefore makes it easy to fork projects, which is pretty useful in open source. But it doesn’t require you to treat each repository as equally authoritative in your workflow. It works just fine with the model of a single centralized repository. It would be foolish if it didn’t, since that’s the way almost every software project works.
The key is that you can fork a branch from the “master” branch, experiment for an hour on the train, and then if you want, you can merge back in, keeping all of your change history. If you can hack on things wherever and whenever you want, and sync back up later, You’re Doing It Right.
Why you shouldn’t fast-forward
As far as I know, git is the only DVCS that has a “fast-forward” merge feature. Maybe that’s why they have it turned on by default. Please, git maintainers, change this default because it is wrong. It’s a clever feature, and when you want it, it’s a nice tool to have around, but default behavior should always be the most commonly-wanted behavior, and normal (non-fast-forward) merges are the most commonly-wanted behavior for a merge.
I didn’t explain fast-forward merges well last time, so I’m going to try again. Let’s imagine you write software for the jukebox in a Waffle House. You have a pretty small codebase so far.
and you decide you want to try hacking on the randomizer code, so that when it plays songs at random, it’s more likely to play songs with “Waffle House” in the name. You make a branch.
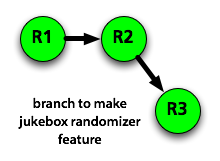
And you hack on it for a while, and it works!
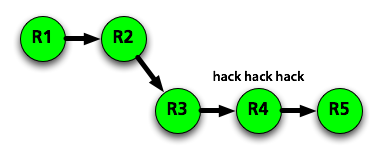
Meanwhile, nobody has been working on the main branch, so nothing has happened
there. It’s time to merge back in so you can release this awesome new code. If
you do this with git merge, it will do a fast-forward merge, meaning it
will just ignore the existence of your branch and pretend that you were
working on the master branch all along. Most importantly, it will not create
a merge point that you can identify later. The information that you ever had a
feature branch is gone.
If you want to revert this feature later (possibly because it’s driving the staff crazy), you have to figure out which changes were involved, and revert them one by one.
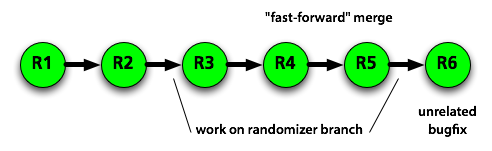
However, if you did a “normal” merge, using git merge --no-ff, there
will be a specific revision marking the merge.
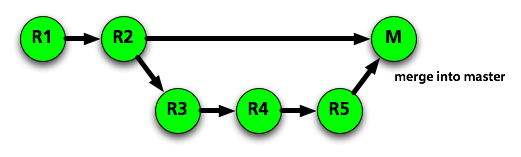
No history is lost. You can see everything that happened on the feature branch if you like, and you can also revert the entire branch by reverting the merge.
Cross merging
One nice feature of DVCS is cheap branching. After figuring out that creating and merging branches is as easy as making a commit, most people jump right in to the workflow of creating a new branch for every bugfix or feature. But you can still get stuck in the “star model”, where every branch is forked and merged only to the master branch. And, as David Yang pointed out, if you have a long-term branch, merging it into master can cause a giant conflict that has to be resolved at the last minute.
It doesn’t have to be that way though. You can and should merge the master
branch into your branch often. This works because DVCS like git use “merge
strategies” that look for the most recent common ancestor revision, and play
through changes from that point forward. Every time you merge master into your
branch, you have a more recent common ancestor (marked with * on the diagram
below), so there is less to merge, and conflicts are resolved on your branch.
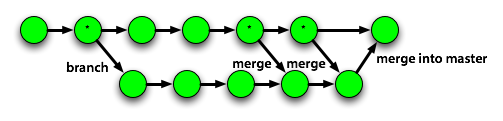
If you do the last merge right before you merge back into master, it won’t even be possible to have conflicts, because you took care of them all. Our deploy system uses this fact, and auto-rejects any branch that won’t merge without conflict. It’s the branch owner’s responsibility to keep each branch merged up to date.
You can also cross-merge between two unrelated branches, which is helpful if they’re dependent on each other. (Maybe fixing bug 13 requires bug 12 to be fixed too.) This has the side effect of making the two branches interdependent, but if they were already interdependent, you’re fine.
Okay, that’s all for this installment!